Creating entity tables
To import and analyze data in Siren Investigate, a structure for the data must exist, which is known as an entity table.
Example
An analyst has received a file that contains some important data about financial transactions between companies and investors of interest.
There is no entity table in the system about financial transactions, so they need to create a new entity table and import the data.
In the Data model app, the analyst can select Create existing table or can import the new data.
Procedure
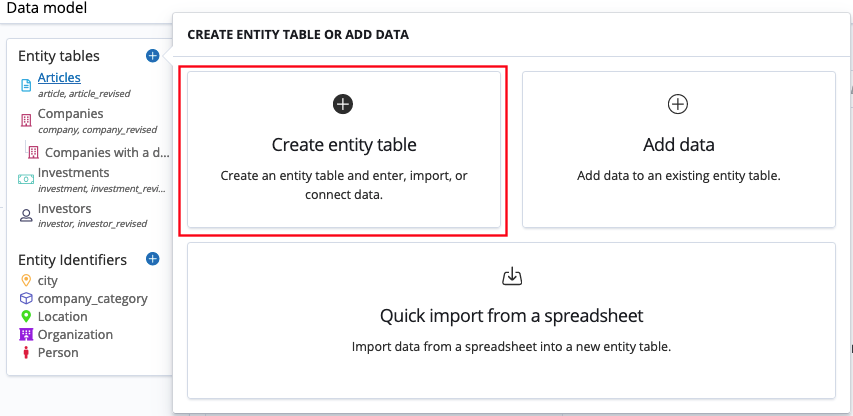
-
In the Data model app, click Add/Create (the plus symbol).
-
Click Create entity table.
-
Create either:
-
A new entity table or;
-
(Advanced) A table that is based on Elasticsearch indices.
-
Creating a new entity table
This option allows you to create an empty table and manually define the fields. The records can then be loaded in bulk or individually.
An Elasticsearch index is created along with the new entity table.
-
Specify a name for the entity table and enter a description.
-
(Optional) Expand the Advanced Settings.
-
You can specify a name for the Elasticsearch index if you want it to be different to the entity table name.
Depending on the type of dataspace configuration you select, a prefix might be added to this name.
-
Select the Dataspace sharing option, which governs the way the data is shared across dataspaces. By default, a new entity table created in a dataspace is set to private, so that the table and its records are visible only within the current dataspace. There are, however, other options. For more information, see Dataspace import options.
-
Shards: Set the number of shards that this index is based on. As of Elasticsearch version 7, the current default value for the number of primary shards per index is 1.
-
Replicas: Set the number of replicas that this index uses. Replicas are copies of the shards.
-
-
Specify a field mapping. These are the definitions of the fields in the entity table, which are technically called mappings. Choose from one of the following options:
-
Add field: Adds an individual field.
-
Add fields from spreadsheet: Uses a spreadsheet (in a common file format, such as
.csv,.tsv,.xls, or.xlsx) as a template for the creation of the entity table. Records can also be loaded directly. For more information, see Importing from a spreadsheet. -
Add fields from datasource: Uses the result of a query to a remote JDBC datasource as a template for the entity table. Data can also be loaded directly after importing data from a datasource.
-
Add fields from network file: Uses a spreadsheet from the server (in a common file format, such as
.csv,.tsv,.xls, or.xlsx) as a template for the creation of the entity table. Records can also be loaded directly. For more information, see importing data from a server file.
-
Continue the import process by selecting one of the following options:
-
Create structure only: Creates an index with the defined mapping, but no records will be imported.
-
Next: Creates an index with the defined mapping and moves on to the transform stage of the import process.
After you create an entity table, you can modify the icon, color, and other values. For more information, see Editing entity tables.
Mapping data in fields
When you are importing data into an entity table, it is important to check and define the mapping.
In the Field mapping section of the screen, most of the data types that are listed in the Type drop-down menus are easy to understand, such as Integer, or Date.
The following are the supported Elasticsearch data types that might occur in your data:
-
text -
keyword -
integer -
short -
long -
double -
float -
date -
boolean -
byte -
binary -
ip -
geo_point -
geo_shape -
date_range -
ip_range -
integer_range -
float_range -
double_range -
long_range
You can validate that the type corresponds to the data correctly by looking at the Samples column. However, if you think that the type does not correspond to your data, you can change it accordingly.
The text and keyword types can be used in the following cases:
-
Text: Use this option for long texts, such as emails and messages. When you choose Text, the back-end system splits the content into individual words and calculates statistics on those words. This allows you to have word clouds and the best level of searchability.
-
Keyword: Use this option for strings that should be considered unbreakable. For example, your dataset might include a field called
Citythat contains strings such as ‘New York’ and ‘Los Angeles’. If you mark this field as Keyword, then the term will be searched for in its entirety, rather than broken into single-word search terms (which would lead to wrong results later). -
Define advanced mapping: This switch gives advanced users the option to add a JSON object to define the mapping in Elasticsearch format. For example, selecting Date and switching the Define advanced mapping switch on allows you to define one or more parsing formats for the date field, such as
{"format":"yyyy-MM-dd HH:mm"}. These formats must match the actual structure of the date in the source documents, otherwise the import will not complete. For more information, see Defining an advanced mapping.
Advanced: From Elasticsearch indices
This option creates an entity table that is based on an existing Elasticsearch index.
This is useful for installations where streams of data are continuously ingested, such as computer logs or streaming messages.
|
By default, the system expects that you are working with log data being fed into Elasticsearch by Logstash. When you create an entity table using this option, indices that match the specified index pattern must exist in Elasticsearch and those indices must contain data. |
To establish the link between Siren Investigate and an Elasticsearch index, you must specify an index pattern.
Defining the index pattern
The index pattern that you enter tells Siren Investigate how to find the relevant index or indices.
To specify multiple indices, you can use the following special characters:
-
Enter the index names separated by a comma (
,). For example, enter the patternmyindex-1,myindex-2to includemyindex-1andmyindex-2but notmyindex. -
Add an asterisk (
*) in the pattern, which matches zero or more characters. For example, enter the patternmyindex-*to match all indices with names that start withmyindex-, such asmyindex,myindex-1, andmyindex-2.
|
The use of a colon ( |
Procedure
When you create an entity table, you can set properties such as the name, icon, and color. You must also specify the following information:
-
Index pattern: Specify an index pattern to identify the Elasticsearch indices that the entity table is based on.
-
Exclude indices: To exclude any Elasticsearch indices from this entity table, add them to the
siren:excludedIndicesproperty in Management → Advanced Settings. -
(Optional) Automatically mark fields that currently contain unique values or single values: If selected, this option analyzes fields and determines which ones contain values that can be used to uniquely identify the data.
This process might take some time run. It can be run at a later time by clicking the Refresh field list on the Fields tab. The values that are generated are approximations, so it is recommended that you check that the properties are correct.
-
Time filter: Select Enable the Time filter based on the following field if you want the entity table to be filterable by time. In the dropdown list that appears, specify a valid time field from the underlying Elasticsearch index.
-
Click Create Table.
-
Click Save.
After you create an entity table, you can modify the icon, color, and other values. For more information, see Editing entity tables.