Introduction to Siren Federate
Welcome to the documentation for Siren Federate version 28.
|
You can select a previous version by using the dropdown menu in the navigation bar. To access all previous versions, go to www.docs.siren.io. |
For a full list of improvements, fixes, and security enhancements, see the release notes .
The Siren Federate plugin extends Elasticsearch with the following main functions:
-
A federation layer that enables the virtualization and querying of remote Elasticsearch clusters.
-
A reflection layer that enables the caching of data from external databases within Elasticsearch.
-
A distributed join layer that enables the execution of join operations at scale.
-
A join-caching layer, based on patent-pending techniques, that enables the caching of the most common join results for faster execution times.
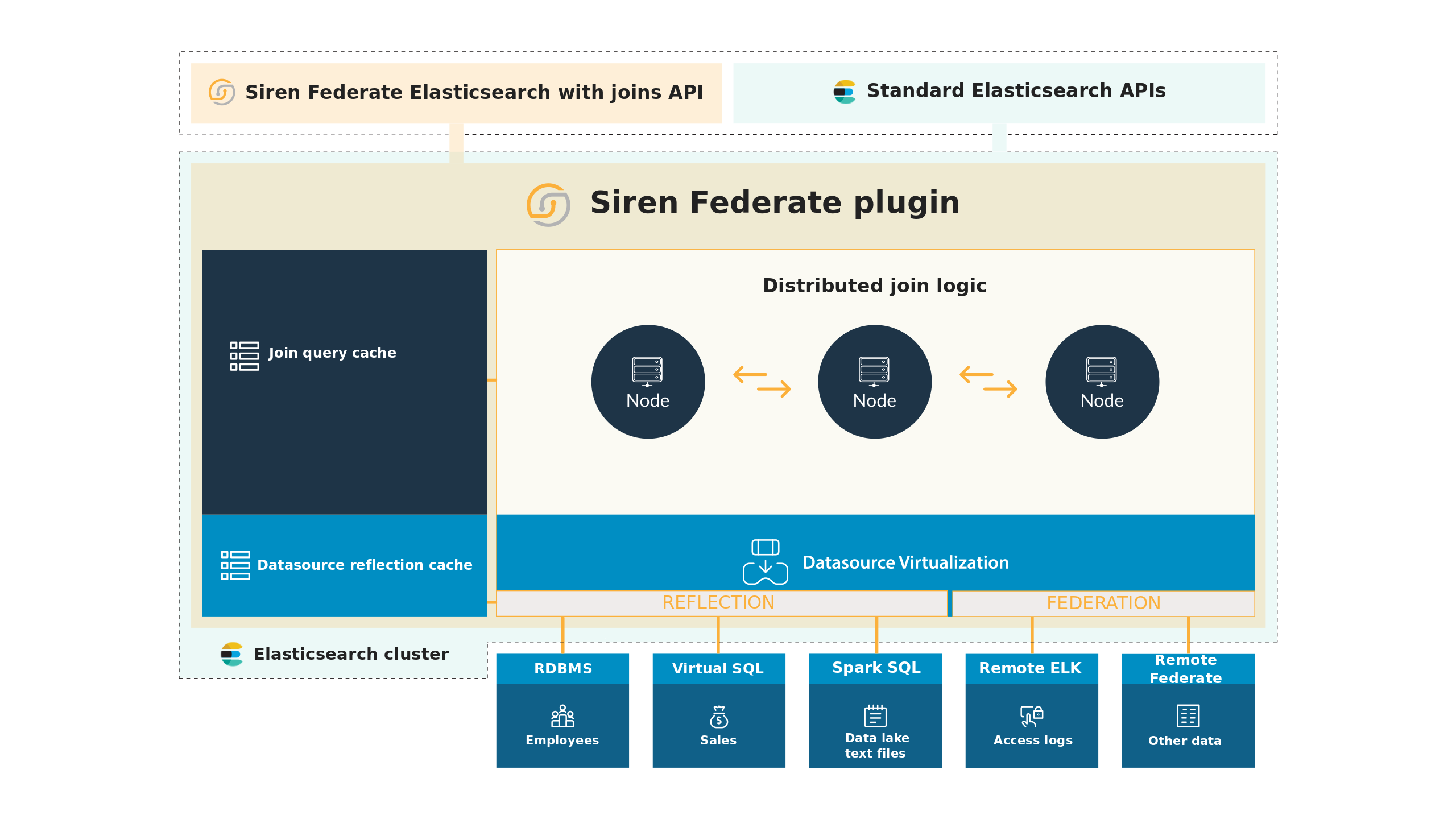
The federation of remote Elasticsearch clusters
Siren Federate provides a module, called Connector, which presents indices from remote Elasticsearch clusters as local to the cluster, denoted as 'virtual indices'.
The connector APIs allow you to register a remote Elasticsearch cluster as a datasource.
After a datasource is registered, an index from the remote cluster can be mapped to a virtual index.
When a request is sent to the virtual index by using an Elasticsearch API, such as the Mapping or Search API, the request is intercepted by the Connector module.
The reflection of external databases
Siren Federate provides a feature, called 'Reflection', which enables the import of data into Elasticsearch from an external datasource. A reflection is a recurrent and fully-managed ingestion that replicates the data from a datasource into an Elasticsearch index.
This can be useful in different scenarios. For example, if a user wants to take advantage of the unique search capabilities of the Elasticsearch back-end system, they might want to decrease the load on the external database system, or they might want to increase the performance, given that Elasticsearch is typically faster than SQL back-end systems (such as Spark SQL) for search and analytics.
A distributed join between indices
Siren Federate extends the Elasticsearch Query DSL with a
join query clause,
which enables the execution of a join operation between two sets of documents, based on a join condition.
To create complex query plans, you can freely combine and nest multiple join query clauses by using boolean operators, such as conjunctions, disjunctions, or negations.
The join condition is based on an equality operator between two fields and is satisfied when documents have equivalent values for the specified fields. The two fields must be of the same data type. Numerical and textual fields are supported.
Siren Federate currently supports two types of join operation: the (left) semi join and the inner join. The join operation is implemented on top of an in-memory distributed computing layer, which scales with the number of nodes available in the cluster. The join operation is parallelized to scale with the number of CPU cores that are available in a machine.
During the execution of a join operation, projected fields from documents are shuffled across the network and stored in memory. The projected fields are encoded in a columnar format using Apache Arrow and stored in the off-heap memory, therefore reducing its impact on the heap memory.
Semi-join
The semi-join is used to filter one set of documents, A, based on a second set of documents, B.
A semi-join between the two sets of documents, A and B, returns the documents of A that satisfy the join condition with the
documents of B. This is equivalent to the EXISTS() operator in SQL.
Inner join
The inner join enables the “projection” of arbitrary fields (including script fields and document’s scores) from a set of documents, B, and “combines” them with a set of documents, A. The projected fields and associated values of a document from set B are mapped to all of the documents from set A that satisfy the join condition. The result of the join is the set of documents, A, augmented by the projected fields from the set of documents, B.
This inner join is useful when there is a need to materialize a view over many disparate records located in multiple data sources.
It is common in log analysis, cyber threat inspection, and intelligence investigation to have diverse recorded events about a particular entity, which are spread across multiple data sources. For example, a user can be linked to one or more sessions and a session can be linked to one or more events, such as login, logout, unauthorized actions, and so on. It is difficult to answer questions such as, “find all of the users who were logged in at time t” or “find all of the users who displayed irregular online activity” from a disparate set of records.
In this scenario, the inner join enables the collection and the grouping of multiple events into a particular context for further analysis.
How does the Siren Federate join compare with the Elasticsearch parent-child model?
The Siren Federate join is similar in nature to the Parent-Child feature of Elasticsearch: they perform a join at query-time. However, there are important differences between them:
-
The parent-child model requires the denormalization of your data model into a hierarchical form. This limits the flexibility of the data modeling and may lead to data redundancy. Siren Federate does not have this data modeling constraint and allows data normalization.
-
The parent document and all of its children must live on the same shard. This limits scalability, because you cannot distribute child documents to other shards or, therefore, to other nodes. The Siren Federate join removes this constraint: it allows you to join documents across shards and across indices.
-
Thanks to the data locality of the parent-child model, the computation of a join does not require transferring data across the network. On the contrary, Siren Federate needs to transfer data across the network while it computes joins across indices, which impacts its performance.
There is no 'one size fits all' solution to this problem, and you need to understand your requirements well to choose the most suitable solution. As a basic rule, if your data model and data relationships are purely hierarchical (or can be mapped to a purely hierarchical model), then the parent-child model might be more appropriate. On the other hand, if you need to query both directions of a data relationship, then the Siren Federate join might be more appropriate.
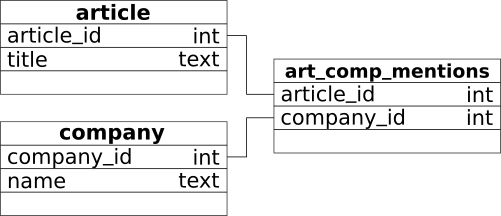
The data model on which the Siren Federate join operates
The most important requirement for executing a join is to have a common shared attribute between two indices.
For example in the diagram below, there is a simple relational data model that is composed of two tables,
article and company, and of one junction table art_comp_mentions to encode the many-to-many relationships
between them.
This model can be mapped to two Elasticsearch indices, article and company, as shown in the diagram below. An
article document will have a multi-valued field mentions with the unique identifiers of the companies mentioned in
the article. In other words, the field mentions is a foreign key in the article table that refers to the primary key
of the company table.
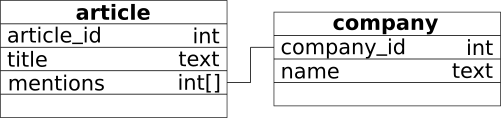
It is possible and uncomplicated to write an SQL statement to flatten and map relationships into a single multi-valued field. Compared to a traditional database model, where a junction table is necessary, the data model can be simplified by taking advantage of multi-valued fields.
Join query cache
Siren Federate provides a query caching mechanism that enables efficient join processing and reduces the query response time. Query caching exploits the idea of reusing cached query results to answer new queries. Caching not only improves the user’s experience, but also reduces the Elasticsearch cluster workload and increases its scalability.
The join query cache in Siren Federate works similarly to the query cache of Elasticsearch. The results of a join query clause, which is a list of document identifiers, are cached efficiently by using a bitset data structure. A semantic definition of the join operation is computed and is used as a signature for the cache entry.
When a new query is received by the system, a signature for each of its join operations is computed and compared with the existing signature that is stored in the cache. The new query can be either totally or partially answered by the cached entries. In the case that it is only partially answered, the query is trimmed based on the cached entries and only the remaining query is executed.
The cache uses an LRU eviction policy: When the cache is full, the least-recently-used query results are evicted to make way for new data. The semantic definition of a join operation captures the lineage and version of its data inputs.
If the data in one of its inputs is modified, then the signature of the join operation will be different. Therefore, the cache entry that is associated with the previous version of the data inputs will become stale and will be evicted.
If an index has one or more replicas, it is important to specify the preference parameter of the search request in order to optimally
take advantage of the join query cache.